1. robots.txt 소개
크롤링은 웹 페이지 상에서 데이터를 가져오는 행위를 말합니다. 파이썬같은 언어로 만든 크롤링 도구를 크롤러라고 부릅니다. 크롤링을 하실 때 확인해야 하는 사항이 있습니다. 바로 robots.txt 입니다.
robots.txt는 검색로봇에게 사이트 및 웹페이지를 수집할 수 있도록 허용하거나 제한하는 국제 권고안입니다. robots.txt 파일은 항상 사이트의 루트 디렉터리에 위치해야 하며 로봇 배제 표준을 따르는 일반 텍스트 파일로 작성해야 합니다.
- 네이버 웹마스터 가이드 -
2. robots.txt 확인하는 방법
robots.txt 파일은 사이트의 루트 디렉토리에 위치하고 있습니다.
메인 홈페이지 주소 뒤에 /robots.txt 붙여서 검색하면 됩니다.
ex) 네이버: https://www.naver.com/robots.txt
티스토리: https://www.tistory.com/robots.txt
3. robots.txt 해석하기
- user-agent: 규칙이 적용되는 크롤러를 식별
- allow: 허용할 디렉토리
- disallow: 비허용할 디렉토리
- *: '모든'
- /$: 첫페이지만 크롤링 허용
네이버의 경우 https://www.naver.com/robots.txt 로 접속하니 robots.txt파일이 다운로드 되었습니다.

해석해보면 다음과 같습니다.
User-agent: * # 모든 크롤링 봇들을 의미
Disallow: / # / 가 들어가는 디렉토리 비허용
Allow: /$ # 첫 페이지만 크롤링 허용/가 들어간 디렉토리는 다 비허용 하지만 /$는 허용하고 있습니다. 이 말은 사이트의 루트 페이지만 수집을 허용한다는 뜻과 같습니다.
제가 지금 포스팅을 작성하고 있는 티스토리도 확인해보겠습니다. ttps://www.tistory.com/robots.txt로 접속하면 브라우저로 연결됩니다.
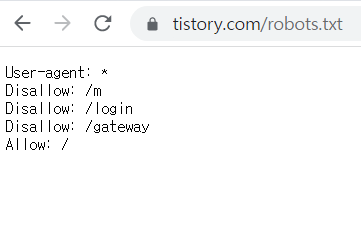
User-agent: * # 모든 크롤링 봇들을 의미
Disallow: /m # /m 디렉토리 비허용
Disallow: /login # /login 디렉토리 비허용
Disallow: /gateway # /gateway 디렉토리 비허용
Allow: / # / 가 들어가는 디렉토리 허용
모든 크롤링 봇들에게 접근을 허용해주는데 /m, /login, /gateway는 허용하지 않고 있습니다. 이 세가지를 제외하고는 접근이 허용 된다는 뜻입니다. /m이 어떤 디렉토리인지 확인하고 싶을 때에 어떻게 할까요? 다음과 같이 URL에 해당 디렉토리를 붙여서 검색해보면 알 수 있습니다.
티스토리
티스토리 앱도 사용해 보시겠어요? 앱을 설치하시면 더욱 편리한 블로그 생활이 가능합니다.
www.tistory.com
특정 봇에게만 권한을 허용해 줄 수도 있습니다. 예제는 다음과 같습니다. 다른 검색엔진의 로봇에 대하여 수집을 허용하지 않고 네이버 검색로봇만 수집을 허용합니다. Yeti는 네이버의 검색엔진을 말합니다. 이 외에도 사이트마다 검색엔진의 이름이 정해져 있습니다. 예를 들어 googlebot-new는 구글 뉴스봇을 말합니다.
User-agent: *
Disallow: /
User-agent: Yeti
Allow: /
4. robots.txt를 꼭 지켜야 하는 것일까?
저는 현재 크롤링하는 프로젝트를 준비하고 있어 공부하다가 robots.txt를 알게 되었습니다. 네이버가 루트 사이트만 허용된 걸 보고 의문이 들었는데요. 네이버는 크롤링 할 때 연습하는 대표적인 사이트이기 때문입니다. 다른 분들이 하시는 걸 많이 보았고 저 또한 네이버 쇼핑을 크롤링 하려는데 법적인 책임을 물어야하는 것인가 궁금해졌습니다.
다행히도 그것은 아니라고 합니다. 앞에서 robots.txt는 권고 안이라고 말씀드렸는데요. "여기는 하지 말아주세요."정도의 요청사항이지 강제성이 있는 것은 아니라고 합니다. 하지만 그렇다고해서 무자비하게 크롤링할 경우 트래픽 과부하를 막기 위해 해당 사이트에서 특정 IP를 차단 할 수 있다고 합니다. 무리한 크롤링은 삼가해주시고 저작권은 꼭 표시해주시기 바랍니다.
- 참고자료
robots.txt 설정하기
robots.txt는 검색로봇에게 사이트 및 웹페이지를 수집할 수 있도록 허용하거나 제한하는 국제 권고안입니다. robots.txt 파일은 항상 사이트의 루트 디렉터리에 위치해야 하며 로봇 배제 표준을 따
searchadvisor.naver.com
robots.txt 확인하고 크롤링(웹스크래핑) 하고 계신가요?
많은 분들이 프로그래밍 언어를 사용해 만든 크롤러, 또는 웹스크래퍼를 이용해서 인터넷 사이트에 있는 웹 사이트의 정보들을 수집합니다. 이러한 행위를 크롤링, 또는 웹스크래핑이라고 하는
redfox.tistory.com
'스터디 > 파이썬' 카테고리의 다른 글
| [Python] 리스트에서 append()와 extend()의 차이점(feat.insert()) (0) | 2022.08.23 |
|---|---|
| [Python] 파이썬 문자열(string) 다루기 - 문자열 함수 (0) | 2022.08.06 |
| [Python] 자료형이 다른 데이터끼리 연산이 가능할까? (0) | 2022.07.23 |
| [Python] 데이터를 json으로 저장하기 (0) | 2022.01.12 |